Answers
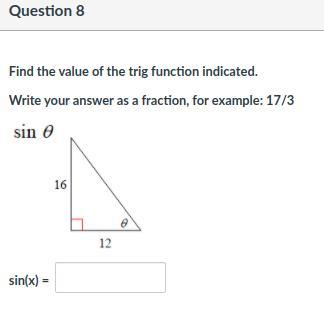
Given opposite = 16
Hypothenuse = ?
Use Pythagorean theorem to find hypothenuse
12^2 + 16^2 = h^2
144 + 256 = h^2
h^2 = 400, h = 20
You know hypothenuse is 20
Opposite/hypothenuse
Solution: 16/20
Simplify if you need to (4/5)
Answer:
[tex]\boxed {\boxed {\sf sin(\theta)=\frac {16}{20}}}[/tex]
Step-by-step explanation:
We are asked to find the sine for the angle indicated. Remember that sine is equal to the opposite over the hypotenuse.
sin(θ)= opposite/hypotenuseAnalyze the triangle given. We have the 2 legs (16 and 12), but we do not have the hypotenuse (the longest side). We must solve for it.
Since this is a right triangle, we can use the Pythagorean Theorem.
[tex]a^2+b^2=c^2[/tex]
Where a and b are the legs and c is the hypotenuse. We know 16 and 12 are the legs.
[tex](16)^2+(12)^2=c^2[/tex]
Solve the exponents.
16²= 16*16=25612²= 12*12= 144[tex]256+144=c^2[/tex]
[tex]400=c^2[/tex]
Since we are solving for c, we must isolate the variable. It is being squared, so we take the inverse: a square root.
[tex]\sqrt{400}=\sqrt{c^2} \\20=c[/tex]
Now we know the hypotenuse is 20. The side opposite of the angle θ is 16.
opposite= 16 hypotenuse=20[tex]sin (\theta)= \frac {opposite}{hypotenuse} \\sin (\theta)= \frac{16}{20}[/tex]
The sine of the angle is equal to 16/20. This can be reduced to 4/5 if necessary (by dividing the numerator and denominator by 4).
Related Questions
A survey of 40 students at a local college asks, "Where do you buy the majority of your books?" The responses fell into three categories: "at the campus bookstore," "on the Internet," and "other." The results follow. Estimate the proportion of the college students who buy their books at the campus bookstore. Where Most Books Bought bookstore bookstore Internet other Internet other bookstore other bookstore bookstore bookstore bookstore bookstore other bookstore bookstore bookstore Internet Internet other other other other other other other Internet bookstore other other Internet other bookstore bookstore other bookstore Internet Internet other bookstore At 98% confidence level, find the margin of error for the proportion of the college students who buy their books from the bookstore?
Answers
At a 98% confidence level, the margin of error for the proportion of college students who buy their books from the bookstore is approximately 1.175.
How to find the margin of error for the proportion of the college students who buy their books from the bookstoreTo find the margin of error for the proportion of college students who buy their books from the bookstore, we can use the formula:
Margin of Error = [tex]\[Z \times \sqrt{\frac{{\hat{p} \cdot (1 - \hat{p}})}{n}}\][/tex]
where:
Z is the z-score corresponding to the desired confidence level (98% confidence level corresponds to a z-score of approximately 2.33)
p_hat is the sample proportion
n is the sample size
From the given data, we can count the number of students who buy their books from the bookstore. In this case, it is 17 students out of 40.
p_hat = 17/40 = 0.425
Substituting the values into the formula, we have:
Margin of Error = [tex]\[2.33 \times \sqrt{\frac{{0.425 \cdot (1 - 0.425)}}{40}}\][/tex]
Calculating the expression inside the square root:
(0.425 * (1 - 0.425)) / 40 = 0.2551
Taking the square root:
[tex]\(\sqrt{0.2551} \approx 0.505\)[/tex]
Finally, we calculate the margin of error:
Margin of Error ≈ 2.33 * 0.505 ≈ 1.175
Therefore, at a 98% confidence level, the margin of error for the proportion of college students who buy their books from the bookstore is approximately 1.175.
Learn more about confidence level at https://brainly.com/question/15712887
#SPJ4
In a food preference experiment, 80 lizards were given the opportunity to choose to eat one of three different species of insects. The results showed that 33 of the lizards chose species A, 12 chose species B, and 35 chose species C. They conducted a Chi- squared analysis to test for equal preference.
They obtained a X² calculated = 15.12, and an X² critical = 5.991.
Write a conclusion for this test. Do not just say "Reject" or "Do Not Reject". Your conclusion must say something about the lizards' preference.
Answers
The analysis indicates that the lizards' preference for the different species of insects is not equal, and there is evidence of a significant difference in preference among the lizards. Therefore, we reject the null hypothesis.
Based on the results of the Chi-squared analysis, we can draw a conclusion regarding the lizards' preference for the three different species of insects.
The calculated Chi-squared value obtained from the experiment is 15.12, and the critical Chi-squared value at the chosen significance level is 5.991.
Comparing the calculated value to the critical value, we find that the calculated value exceeds the critical value.
This indicates that the difference in preference among the lizards for the different species of insects is statistically significant.
In other words, the observed distribution of choices among the lizards significantly deviates from the expected distribution under the assumption of equal preference.
Therefore, we reject the null hypothesis of equal preference. This means that the lizards do not have an equal preference for the three species of insects.
The experiment suggests that there is a significant variation in preference among the lizards, with some species of insects being preferred over others.
To know more about null hypothesis refer here:
https://brainly.com/question/30821298#
#SPJ11
There are classes. (Type a whole number.) (b) The lower class limit for the first class is (Type an integer or a decimal. Do not round.) The upper class limit for the first class is (Type an integer or a decimal. Do not round.) (c) The class width is (Type an integer or a decimal. Do not round.) Speed (km/hr) 10-13.9 14-17.9 18-21.9 22-25.9 26-29.9 30-33.9 Number of Players 4 7 20 80 268 237 (a) und number of classes, (b) the class limits for the first class, and (c) the class width.
Answers
Here, there are 6 classes, with the first class having a lower class limit of 10, an upper class limit of 13.9, and a class width of 3.9.
(a) The number of classes can be determined by counting the distinct ranges of the data. In this case, we have 6 distinct ranges: 10-13.9, 14-17.9, 18-21.9, 22-25.9, 26-29.9, and 30-33.9. Therefore, the number of classes is 6.
(b) The lower class limit for the first class is 10, as it represents the lower end of the range 10-13.9.
(c) The upper class limit for the first class is 13.9, as it represents the upper end of the range 10-13.9.
To calculate the class width, we subtract the lower class limit of the first class from the upper class limit of the first class: 13.9 - 10 = 3.9. Therefore, the class width is 3.9.
Learn more about lower class limit here, https://brainly.com/question/30336091
#SPJ11
1. Suppose A
2.Then B is bounded below.
3. Let x = lub(A).
4. Then -x = glb(B).
a) Explain why (2) is true.
b) Explain why lub(A) exists.
c) Explain why (4) is true.
d)Deduce that if B
Answers
Hence, −u = glb(A) = lub(−A), and u + x = sup(C − A) = lub(C) − glb(A).
a) Bounded below means that there is a number x such that for all y in B, x ≤ y. Since x is an upper bound of A, it follows that x is a lower bound of B. Hence, B is bounded below.
b) Any non-empty set of real numbers that is bounded above has a least upper bound. Since A is bounded above (by any upper bound of B, for instance), it follows that A has a least upper bound.
c) By the definition of the least upper bound, x is an upper bound of A, and for any ε > 0, there exists a ∈ A such that x − ε < a. Since x is an upper bound of A, it follows that −x is a lower bound of B. By a), B is also bounded below, hence it has a greatest lower bound. Let y = glb(B). Then for any ε > 0, there exists b ∈ B such that b < y + ε, which implies that −(y + ε) < −b. Since −x is a lower bound of B, it follows that −x ≤ −b for all b ∈ B, hence −x ≤ y + ε for all ε > 0. Thus, −x ≤ y.
d) Suppose B is non-empty and bounded above, and let z = sup(B). Then for any ε > 0, there exists b ∈ B such that b > z − ε. Since x is the least upper bound of A, there exists a ∈ A such that a > x − ε. Then a + b > x − ε + z − ε = (x + z) − 2ε. Since ε was arbitrary, it follows that x + z is the least upper bound of the set C = {a + b | a ∈ A, b ∈ B}. In particular, C is non-empty and bounded above, hence it has a least upper bound. Let w = lub(C), and let ε > 0 be given. Then there exist a ∈ A and b ∈ B such that a + b > w − ε. Since x is the least upper bound of A, there exists a' ∈ A such that a' > x − ε. Then a' + b > w − ε + ε = w, which implies that w is an upper bound of C. By the definition of the least upper bound, it follows that w ≤ x + z. Since −x = glb(B), it follows that −x ≤ z, hence w ≤ x − (−x) = 2x. But x + z ≤ 2x, hence w ≤ x + z ≤ 2x. Since x is an upper bound of A, it follows that −x is a lower bound of −A, hence by a), −A is bounded below. Let u = glb(−A). Then u + x = glb(C − A), where C − A = {b − a | a ∈ A, b ∈ B}. But B is bounded below, hence C − A is also bounded below, and glb(C − A) exists. Hence, u + x is the greatest lower bound of C − A. Let ε > 0 be given. Then there exist a ∈ A and b ∈ B such that a + b < u + x + ε. Since u is the greatest lower bound of −A, it follows that −a > −u. Then b − (u + a) < x + ε, hence b − (u + a) < ε. Since ε was arbitrary, it follows that u + x is an upper bound of C − A. By the definition of the least upper bound, it follows that u + x = sup(C − A). Hence, −u = glb(A) = lub(−A), and u + x = sup(C − A) = lub(C) − glb(A).
To know more about bound,
https://brainly.com/question/21734499
#SPJ11
Find the general solution of the given differential equation.
y'' + 4y = t²e³ᵗ + 3
Answers
The general solution of the differential equation is 4A + 2B = 1 (coefficient of t²e³ᵗ).
To find the general solution of the given differential equation y'' + 4y = t²e³ᵗ + 3, we can use the method of undetermined coefficients.
The homogeneous equation associated with the given equation is y'' + 4y = 0, which has the characteristic equation r² + 4 = 0. The roots of this equation are r = ±2i, indicating that the homogeneous solution is of the form y_h(t) = c₁cos(2t) + c₂sin(2t), where c₁ and c₂ are constants.
To find the particular solution, we assume that the particular solution has the form y_p(t) = A(t) + B, where A(t) represents the particular solution related to the term t²e³ᵗ and B represents the particular solution related to the constant term 3.
Differentiating y_p(t), we have:
y'_p(t) = A'(t)
y''_p(t) = A''(t)
Substituting these derivatives into the original differential equation, we get:
A''(t) + 4(A(t) + B) = t²e³ᵗ + 3
To match the right-hand side, we set A''(t) + 4A(t) = t²e³ᵗ and 4B = 3.
The solution to the equation A''(t) + 4A(t) = t²e³ᵗ can be found using the method of undetermined coefficients. Since the right-hand side includes t²e³ᵗ, we assume a particular solution of the form A_p(t) = (At² + Bt + C)e³ᵗ, where A, B, and C are constants.
Differentiating A_p(t), we have:
A'_p(t) = (2At + B)e³ᵗ + (At² + Bt + C)3e³ᵗ
A''_p(t) = (2A + 2A + 2B)e³ᵗ + (2At + B)3e³ᵗ + (2At + Bt + C)9e³ᵗ
= (4A + 2B)e³ᵗ + (6At + 3B + 9A + 3Bt + 9C)e³ᵗ
= (4A + 2B + 6At + 3Bt + 9A + 9C)e³ᵗ
Substituting these derivatives into the equation A''(t) + 4A(t) = t²e³ᵗ, we get:
(4A + 2B + 6At + 3Bt + 9A + 9C)e³ᵗ + 4(At² + Bt + C)e³ᵗ = t²e³ᵗ
Matching the coefficients of like terms on both sides, we have:
(4A + 2B) + 6A = 0 (coefficient of e³ᵗ)
(3B + 9C) = 0 (coefficient of e³ᵗ)
4C = 0 (coefficient of e³ᵗ)
4A + 2B = 1 (coefficient of t²e³ᵗ)
From the first equation, we get A = -B/2, and substituting this into the fourth equation, we get B = 1/14. Substituting these values of A and B into the second equation
Learn more about differential equation here
https://brainly.com/question/1164377
#SPJ11
3400+dollars+is+placed+in+an+account+with+an+annual+interest+rate+of+8.25%.+how+much+will+be+in+the+account+after+25+years,+to+the+nearest+cent?
Answers
To find the amount in the account after 25 years, we can use the formula for compound interest which is given by;A = P (1 + r/n)^(nt) where;A = the final amount P = the principal or initial amount of dollarsr = the annual interest rate as a decimaln = the number of times the interest is compounded per yeart = the number of years So, for the given question;P = 3400 dollarsr = 8.25% per annum = 0.0825n = 1 (annually)t = 25 yearsSubstituting the values in the formula;A = 3400(1 + 0.0825/1)^(1×25) = 3400(1.0825)^25 = 3400 × 4.27022 = 14531.746 dollarsTherefore, the amount in the account after 25 years, to the nearest cent is $14531.75.
To calculate the future value of the account after 25 years, we can use the formula for compound interest:
A = P(1 + r/n)^(nt)
Where:
A = Final amount (future value)
P = Principal amount (initial deposit)
r = Annual interest rate (as a decimal)
n = Number of times interest is compounded per year
t = Number of years
In thiS case, the principal amount (P) is $3400, the annual interest rate (r) is 8.25% or 0.0825 as a decimal, the number of times interest is compounded per year (n) is not specified, so we will assume it is compounded annually (n = 1), and the number of years (t) is 25.
Plugging in these values into the formula:
A = 3400(1 + 0.0825/1)^(1*25)
Simplifying the expression:
A = 3400(1.0825)^25
Calculating the value using a calculator or computer:
A ≈ 3400(3.368599602) ≈ $11,458.83
Therefore, to the nearest cent, the amount in the account after 25 years will be approximately $11,458.83.
To know more about compounded, visit:
https://brainly.com/question/28020457
#SPJ11
Given the following data: An initial amount of $3400 is placed in an account with an annual interest rate of 8.25%. We are to determine the amount in the account after 25 years, to the nearest cent.
Therefore, the amount in the account after 25 years, to the nearest cent is $23956.35.
The formula for the compound interest is given by;
[tex]P(1 + r/n)^{nt}[/tex]
Where; P is Principal amount (the initial amount you borrow or deposit), r is Annual interest rate (as a decimal), n is Number of times the interest is compounded per year (in this case, it's annual, therefore n = 1), t is Number of years.
Hence, the amount in the account after 25 years is;
[tex]P(1 + r/n)^{nt} = $3400(1 + 0.825 / 1)^{1 \times25}[/tex]
[tex]= 3400(1.0825)^{25}[/tex]
[tex]= $3400 \times 7.04567[/tex]
= $23956.35
Therefore, the amount in the account after 25 years, to the nearest cent is $23956.35.
To know more about compound interest visit
https://brainly.com/question/22803385
#SPJ11
what is the period of the graph of y=2cos(pi/2 x)+3
Answers
The period of the graph of the function [tex]\(y = 2\cos\left(\frac{\pi}{2}x\)+3\))[/tex] is 4.
The period of a cosine function is the distance it takes for the function to complete one full cycle or repeat itself. In this case, we have the function [tex]\(y = 2\cos\left(\frac{\pi}{2}x\)+3\))[/tex].
The general form of the cosine function is [tex]\(y = A\cos(Bx+C) + D\)[/tex], where A represents the amplitude, B represents the frequency or the reciprocal of the period, C represents the phase shift, and D represents the vertical shift.
Comparing our given function with the general form, we can see that A = 2, [tex]B = \(\frac{\pi}{2}\)[/tex], C = 0, and D = 3.
The frequency or the reciprocal of the period is given by B. In this case, [tex]B = \(\frac{\pi}{2}\)[/tex].
To find the period, we can use the formula:
Period = [tex]\(\frac{2\pi}{|B|}\)[/tex]
Substituting the value of B, we get:
Period = [tex]\(\frac{2\pi}{\left|\frac{\pi}{2}\right|}\)[/tex]
Simplifying further:
Period = [tex]\(\frac{2\pi}{\frac{\pi}{2}}\)[/tex]
Period = 4
Therefore, the period of the graph of the function [tex]\(y = 2\cos\left(\frac{\pi}{2}x\)+3\))[/tex] is 4.
For more questions on cosine function
https://brainly.com/question/26993851
#SPJ8
During the winter, 42% of the patients of a walk-in clinic come because of symptoms of the common cold or flu. a. What is the probability that, of the 32 patients on one winter morning, exactly 10 had symptoms of the common cold or flu?
Answers
Given: During winter, 42% of patients in the walk-in clinic come because of symptoms of the common cold or flu.
We have to find the probability that, out of 32 patients on one winter morning, exactly 10 had symptoms of the common cold or flu. The probability distribution of binomial experiment is given by: P(x) = (nCx) * p^x * q^(n - x)Where, n = number of trials, p = probability of success, q = probability of failure = (1 - p)x = number of successes, n - x = number of failures.
a) Here, we have n = 32, x = 10, p = 0.42, q = 0.58.P(x = 10) = (nCx) * p^x * q^(n - x). Putting the values we get,
P(x = 10) = (32C10) * (0.42)^10 * (0.58)^(32-10)≈ 0.189b) The probability of having exactly 8 patients with symptoms of the common cold or flu is given by: P(x = 8) = (nCx) * p^x * q^(n - x). Putting the values we get, P(x = 8) = (32C8) * (0.42)^8 * (0.58)^(32-8)≈ 0.218. Therefore, the probability that, of the 32 patients on one winter morning, exactly 10 had symptoms of the common cold or flu is approximately 0.189.
The probability that, of the 32 patients on one winter morning, exactly 8 had symptoms of the common cold or flu is approximately 0.218.
To know more about probability, click here:
https://brainly.com/question/31828911
#SPJ11
use the value of the linear correlation coefficient to calculate the coefficient of determination.what does this tell you about the explained variation of the data about the regression line? About the unexplained variation?
Answers
It measures the proportion of the total variation in the dependent variable that is explained by the independent variable(s). The coefficient of determination tells us about the explained variation of the data about the regression line and the unexplained variation.
The coefficient of determination, denoted as R^2, is calculated by squaring the value of the linear correlation coefficient (r). It represents the proportion of the total variation in the dependent variable that is explained by the independent variable(s) in a regression model.
R^2 ranges from 0 to 1, where 0 indicates that none of the variation is explained by the model, and 1 indicates that all of the variation is explained. A higher R^2 value indicates a stronger relationship between the independent and dependent variables.
The coefficient of determination provides insights into the explained and unexplained variation in the data. The explained variation refers to the part of the total variation that can be accounted for by the regression model, representing the portion of the data that is predictable or explained by the independent variable(s). On the other hand, the unexplained variation represents the portion of the data that is not accounted for by the regression model, reflecting the random or unpredictable part of the data.
In summary, a higher R^2 value indicates that a larger proportion of the total variation is explained by the regression model, suggesting a better fit. Conversely, a lower R^2 value implies that a smaller proportion of the total variation is explained, indicating a weaker fit and more unexplained variation in the data.
To learn more about regression model click here: brainly.com/question/31969332
#SPJ11
how much money is needed is needed to withdraw $60 per month for
6 years if the interest rate is 7% compounded monthly?
Answers
Approximately $4,956.10 is needed to withdraw $60 per month for 6 years at a 7% interest rate compounded monthly.
To calculate how much money is needed to withdraw $60 per month for 6 years with a 7% interest rate compounded monthly, we can use the formula for the future value of an annuity.
The formula for the future value of an annuity is:
FV = P * ((1 + r)^n - 1) / r
Where:
FV = Future Value
P = Payment per period
r = Interest rate per period
n = Number of periods
In this case, the payment per period (P) is $60, the interest rate per period (r) is 7%/12 (monthly compounding), and the number of periods (n) is 6 years * 12 months/year = 72 months.
Substituting the values into the formula, we have:
FV = $60 * ((1 + 0.07/12)^72 - 1) / (0.07/12)
Calculating this expression, we find:
FV ≈ $4,956.10
To know more about interest rate refer here:
https://brainly.com/question/28272078#
#SPJ11
1. The probability that a patient recovers from a delicate heart operation is 0.9. What is the probability that exactly 4 of the next 6 patients having this operation survive? 2. The probability that a patient recovers from a delicate heart operation is 0.9. What is the probability that the 4th surviving patients is the 6th patients? 3. The probability that a patient recovers from a delicate heart operation is 0.9. What is the probability that the 1st surviving patients is the 4th patients?
Answers
The probability that exactly 4 out of the next 6 patients survive a delicate heart operation can be calculated using the binomial probability formula. The probability is approximately 0.186.
The probability that the 4th surviving patient is the 6th patient can be calculated using the binomial probability formula as well. The probability is approximately 0.040.
The probability that the 1st surviving patient is the 4th patient can also be calculated using the binomial probability formula. The probability is approximately 0.194.
To calculate the probability that exactly 4 out of the next 6 patients survive, we can use the binomial probability formula. The formula is P(X = k) = C(n, k) * p^k * (1-p)^(n-k), where P(X = k) is the probability of k successes, n is the total number of trials, p is the probability of success, and C(n, k) is the number of combinations of n items taken k at a time.
In this case, we want to calculate P(X = 4) where n = 6 (total number of patients) and p = 0.9 (probability of a patient surviving). Plugging these values into the formula, we get P(X = 4) = C(6, 4) * 0.9^4 * (1-0.9)^(6-4) ≈ 0.186.
To find the probability that the 4th surviving patient is the 6th patient, we need to consider the sequence of surviving patients. Since there are only two outcomes (surviving or not surviving) for each patient, we can think of this as a Bernoulli trial. The probability of the 6th patient being the 4th survivor can be calculated using the binomial probability formula.
Here, we want to calculate P(X = 4) where n = 5 (number of trials until the 4th success occurs) and p = 0.9 (probability of success). Plugging these values into the formula, we get P(X = 4) = C(5, 4) * 0.9^4 * (1-0.9)^(5-4) ≈ 0.040.
Similarly, to find the probability that the 1st surviving patient is the 4th patient, we need to consider the sequence of surviving patients. Again, we can treat this as a Bernoulli trial and calculate the probability using the binomial probability formula.
In this case, we want to calculate P(X = 1) where n = 3 (number of trials until the 1st success occurs) and p = 0.9 (probability of success). Plugging these values into the formula, we get P(X = 1) = C(3, 1) * 0.9^1 * (1-0.9)^(3-1) ≈ 0.194.
To learn more about probability
Click here brainly.com/question/16988487
#SPJ11
Which of the following is NOT a technique used in variable selection? A. LASSO B. principal components analysis C. VIF regression D. stepwise regression
Answers
The technique that is NOT used in variable selection is principal components analysis. Thus, option (B) is the correct option.
Variable selection is the process of selecting the appropriate variables (predictors) to incorporate in the statistical model. It is an important step in the modeling process, especially in multiple linear regression.
The technique(s) used in variable selection may vary depending on the purpose of the analysis and the features of the data.
There are various methods and techniques for variable selection, such as stepwise regression, ridge regression, lasso, and VIF regression. However, principal components analysis is not a variable selection technique but rather a dimensionality reduction technique.
PCA is used to reduce the number of predictors (variables) by transforming them into a smaller set of linearly uncorrelated variables known as principal components.
To learn more about regression, refer below:
https://brainly.com/question/32505018
#SPJ11
Consider the solid that lies above the square (in the xy-plane) R=[0,2]×[0,2], and below the elliptic paraboloid z=100−x^2−4y^2.
(A) Estimate the volume by dividing R into 4 equal squares and choosing the sample points to lie in the lower left hand corners.
(B) Estimate the volume by dividing R into 4 equal squares and choosing the sample points to lie in the upper right hand corners..
(C) What is the average of the two answers from (A) and (B)?
(D) Using iterated integrals, compute the exact value of the volume.
2) Find ∬R f(x,y)dA where f(x,y)=x and R=[3,4]×[2,3].
∬Rf(x,y)dA=
Answers
(A) The estimated volume of the elliptic paraboloid using the lower left corners as sample points are V ≈ 97.
(B) The estimated volume using the upper right corners as sample points is V ≈ 92.
(C) The average of the two estimates is V ≈ 94.5.
(D) The exact value of the volume using iterated integrals is V = 2.5.
(A) To estimate the volume by dividing R into 4 equal squares and choosing the sample points to lie in the lower left-hand corners:
Divide the x-axis into 2 equal intervals: [0, 1] and [1, 2].
Divide the y-axis into 2 equal intervals: [0, 1] and [1, 2].
Choose the sample points to be the lower left corners of each square: (0, 0), (1, 0), (0, 1), (1, 1).
Calculate the height of each square by substituting the sample points into the equation of the elliptic paraboloid: z = 100 - x² - 4y².
For the sample points, we get the heights: z1 = 100, z2 = 96, z3 = 96, z4 = 92.
Calculate the area of each square: ΔA = (2/4)² = 1/4.
Estimate the volume by multiplying the area of each square by its corresponding height and summing them up: V ≈ (1/4)(100 + 96 + 96 + 92) = 97.
(B) To estimate the volume by dividing R into 4 equal squares and choosing the sample points to lie in the upper right-hand corners, we follow the same steps as in (A), but this time we choose the sample points to be the upper right corners of each square: (1, 1), (2, 1), (1, 2), (2, 2).
Calculating the heights and estimating the volume, we get V ≈ (1/4)(96 + 92 + 92 + 88) = 92.
(C) The average of the two estimates from (A) and (B) is (97 + 92)/2 = 94.5.
(D) To compute the exact value of the volume using iterated integrals, we integrate the function f(x, y) = 100 - x² - 4y² over the region R=[0,2]×[0,2]:
∬R f(x, y) dA = ∫[0,2] ∫[0,2] (100 - x² - 4y²) dy dx
To evaluate the double integral ∬R f(x, y) dA, where f(x, y) = x and R = [3, 4] × [2, 3], we integrate the function over the given region as follows:
∬R f(x, y) dA = ∫[2,3] ∫[3,4] x dy dx
Integrating with respect to y first:
∫[2,3] ∫[3,4] x dy dx = ∫[2,3] (xy) [3,4] dx
= ∫[2,3] (4x - 3x) dx
= ∫[2,3] (x) dx
= (1/2)x² | [2,3]
= (1/2)(3)² - (1/2)(2)²
= (1/2)(9) - (1/2)(4)
= 4.5 - 2
= 2.5
Therefore, the result of the double integral ∬R f(x, y) dA is 2.5.
Learn more about elliptic paraboloid at
https://brainly.com/question/30882626
#SPJ4
The length of a common housefly has approximately a normal distribution with mean µ= 6.4 millimeters and a standard deviation of σ= 0.12 millimeters. Suppose we take a random sample of n=64 common houseflies. Let X be the random variable representing the mean length in millimeters of the 64 sampled houseflies. Let Xtot be the random variable representing sum of the lengths of the 64 sampled houseflies
a) About what proportion of houseflies have lengths between 6.3 and 6.5 millimeters? ______
b) About what proportion of houseflies have lengths greater than 6.5 millimeters? _______
c) About how many of the 64 sampled houseflies would you expect to have length greater than 6.5 millimeters? (nearest integer)?______
d) About how many of the 64 sampled houseflies would you expect to have length between 6.3 and 6.5 millimeters? (nearest integer)?________
e) What is the standard deviation of the distribution of X (in mm)?________
f) What is the standard deviation of the distribution of Xtot (in mm)? ________
g) What is the probability that 6.38 < X < 6.42 mm ?____________
h) What is the probability that Xtot >410.5 mm? ____________
Answers
(a) Proportion of houseflies have lengths between 6.3 and 6.5 millimeters is 0.5934.
(b) Proportion of houseflies have lengths greater than 6.5 millimeters is 20.33%.
c) 64 sampled houseflies would expect to have length greater than 6.5 millimeters is 13 .
d) 64 sampled houseflies would expect to have length between 6.3 and 6.5 millimeters is 38 .
e) The standard deviation of the distribution of X is 0.015 millimeters.
f) The standard deviation of the distribution of X to t is 0.96 millimeters.
g) The probability that 6.38 < X < 6.42 mm is 0.1312 .
h) The probability that Xtot >410.5 mm is 0 .
(a) To determine the proportion of houseflies with lengths between 6.3 and 6.5 millimeters, we need to calculate the area under the normal distribution curve between these two values.
Using the Z-score formula:
Z = (X - µ) / σ
For X = 6.3 mm:
Z₁ = (6.3 - 6.4) / 0.12 = -0.833
For X = 6.5 mm:
Z₂ = (6.5 - 6.4) / 0.12 = 0.833
Now we can use a standard normal distribution table or calculator to find the proportion associated with the Z-scores:
P(-0.833 < Z < 0.833) ≈ P(Z < 0.833) - P(Z < -0.833)
Looking up the values in a standard normal distribution table or using a calculator, we find:
P(Z < 0.833) ≈ 0.7967
P(Z < -0.833) ≈ 0.2033
Therefore, the proportion of houseflies with lengths between 6.3 and 6.5 millimeters is approximately:
0.7967 - 0.2033 = 0.5934
(b) To find the proportion of houseflies with lengths greater than 6.5 millimeters, we need to calculate the area under the normal distribution curve to the right of this value.
P(X > 6.5) = 1 - P(X < 6.5)
Using the Z-score formula:
Z = (X - µ) / σ
For X = 6.5 mm:
Z = (6.5 - 6.4) / 0.12 = 0.833
Using a standard normal distribution table or calculator, we find:
P(Z > 0.833) ≈ 1 - P(Z < 0.833)
≈ 1 - 0.7967
≈ 0.2033
Therefore, approximately 20.33% of houseflies have lengths greater than 6.5 millimeters.
c) The number of houseflies with lengths greater than 6.5 millimeters can be approximated by multiplying the total number of houseflies (n = 64) by the proportion found in part (b):
Expected count = n * proportion
Expected count = 64 * 0.2033 ≈ 13 (nearest integer)
Therefore, we would expect approximately 13 houseflies out of the 64 sampled to have lengths greater than 6.5 millimeters.
d) Similarly, to find the expected number of houseflies with lengths between 6.3 and 6.5 millimeters, we multiply the total number of houseflies (n = 64) by the proportion found in part (a):
Expected count = n * proportion
Expected count = 64 * 0.5934 ≈ 38 (nearest integer)
Therefore, we would expect approximately 38 houseflies out of the 64 sampled to have lengths between 6.3 and 6.5 millimeters.
(e) The standard deviation of the distribution of X (the mean length of the 64 sampled houseflies) can be calculated using the formula:
Standard deviation of X = σ /√(n)
σ = 0.12 millimeters and n = 64, we have:
Standard deviation of X = 0.12 / √(64)
= 0.12 / 8
= 0.015 millimeters
Therefore, the standard deviation of the distribution of X is 0.015 millimeters.
f) The standard deviation of the distribution of Xtot (the sum of the lengths of the 64 sampled houseflies) can be calculated using the formula:
Standard deviation of Xtot = σ * √(n)
Given σ = 0.12 millimeters and n = 64, we have:
Standard deviation of Xtot = 0.12 * √(64)
= 0.12 * 8
= 0.96 millimeters
Therefore, the standard deviation of the distribution of Xtot is 0.96 millimeters.
g) To find the probability that 6.38 < X < 6.42 mm, we need to calculate the area under the normal distribution curve between these two values.
Using the Z-score formula:
Z₁ = (6.38 - 6.4) / 0.12 = -0.167
Z₂ = (6.42 - 6.4) / 0.12 = 0.167
Using a standard normal distribution table or calculator, we find:
P(-0.167 < Z < 0.167) ≈ P(Z < 0.167) - P(Z < -0.167)
P(Z < 0.167) ≈ 0.5656
P(Z < -0.167) ≈ 0.4344
Therefore, the probability that 6.38 < X < 6.42 mm is approximately:
0.5656 - 0.4344 = 0.1312
(h) To find the probability that Xtot > 410.5 mm, we need to convert it to a Z-score.
Z = (X - µ) / σ
For X = 410.5 mm:
Z = (410.5 - (6.4 * 64)) / (0.12 * (64))
= (410.5 - 409.6) / 0.015
= 60
Using a standard normal distribution table or calculator, we find:
P(Z > 60) ≈ 1 - P(Z < 60)
≈ 1 - 1
≈ 0
Therefore, the probability that Xtot > 410.5 mm is approximately 0.
Learn more about the Probability here: https://brainly.com/question/25839839
#SPJ11
this is 9t grade math. ddhbhb
Answers
The domain and range of the line given is expressed s:
Domain: x ≥ 0
Rangel: y ≥ 0
Determining the domain and range of a function
The given graph is a line graph. The domain of the graph are the values along the line lying on the x-components while the range are the values lying along the y-axis.
Since the line projects from the origin to infinity, hence the domain of the line will be (0, ∞) while the range of the graph is also (0, ∞).
The domain and range can also be expressed as:"
Domain: x ≥ 0
Rangel: y ≥ 0
Learn more on domain and range here: https://brainly.com/question/10197594
#SPJ1
Daily air quality is measured by the air quality index (AQI) reported by the Environmental Protection Agency. This index reports the pollution level and what associated health effects might be a concern. The index is calculated for five major air pollutants regulated by the Clean Air Act and takes values from 0 to 300, where a higher value indicates lower air quality. AQI was reported for a sample of 91 days in 2011 in Durham, NC. The relative frequency histogram below shows the distribution of the AQI values on these days. 0.20 0.12 0.10 0.08 0.08 0.08 0.08 0.08 0.07 0.06 0.04 0.04- 0.00 10 20 30 40 50 70 daily AQI value a) Estimate the median AQI value of this sample. Median = b) Estimate Q1, Q3, and IQR for this distribution. Q1 = Q3 IQR = 0.15 0.10 0.05 50.06 0.05 0.06 60
Answers
Q1 = 30.00, Q3 = 50.00, and IQR = Q3 - Q1 = 50.00 - 30.00 = 20.00.
Median AQI value = 40.00b) Q1 = 30.00, Q3 = 50.00, IQR = 20.00
The given frequency histogram represents the distribution of the AQI values.
We need to find the median and the quartiles for this distribution.
Median: The median of the given data can be calculated as follows: The cumulative frequency of the class interval containing the median is equal to the total frequency divided by 2.
Median lies in the class 40-50, so class width = 10. Number of values below median = (91/2) = 45.5.
Median lies 5.5 above the lower limit of 40-50, hence median is 40. Q1, Q3, and IQR: To calculate Q1, we first need to find the cumulative frequency for the class interval containing Q1.
Q1 is the 25th percentile of the data. So the cumulative frequency for Q1 is (25/100) × 91 = 22.75. Q1 lies in the class 30-40, so class width = 10.
Q1 = lower limit of class interval + [(cumulative frequency of previous class interval - cumulative frequency of class interval containing Q1)/frequency of class interval containing Q1] × class width = 30 + [(22.75 - 20)/8] × 10 = 30 + 0.34 × 10 = 33.4 ≈ 30.
To calculate Q3, we first need to find the cumulative frequency for the class interval containing Q3. Q3 is the 75th percentile of the data. So the cumulative frequency for Q3 is (75/100) × 91 = 68.25.
Q3 lies in the class 50-60, so class width = 10. Q3 = lower limit of class interval + [(cumulative frequency of previous class interval - cumulative frequency of class interval containing Q3)/frequency of class interval containing Q3] × class width = 50 + [(68.25 - 60)/11] × 10 = 50 + 0.73 × 10 = 56.3 ≈ 60. Therefore, Q1 = 30.00, Q3 = 50.00, and IQR = Q3 - Q1 = 50.00 - 30.00 = 20.00.
Know more about Median here:
https://brainly.com/question/11237736
#SPJ11
Recall the definitions of an irreducible number and a prime number. According to these definitions, (a) why is 12 not a prime number? (b) why is 14 not an irreducible number?
Answers
12 is not a prime number because it is divisible by 2 and 14 not an irreducible number because it is neither 1 nor -1
What is an irreducible number?Recall that a prime number p is an integer greater than 1 such that given integers m and n, if p|mn then either p|m or p|n. Also, a prime number has only two factors.
An irreducible is an integer t (which is neither 1 nor -1) which has the property that it is divisible only by ±1 and ±t. All prime numbers are irreducible, and all positive irreducible are prime.
From the definitions, 12 is not a prime number because it has more than two factors
Factors of 12 = 1,2,3,4,6,12
14 Can be divided by ±1 and ±t
where t is neither 1 nor -1
Learn more about prime numbers on https://brainly.com/question/29629042
#SPJ4
solve the integral given below with appropriate &, F and values, using the Beta function x² (1-x²³) dx = ?
Answers
The solution to the integral using the beta function is, (1/3) x³ - (1/8) x^8 + C.
The given integral is,∫x² (1-x²³) dx
We can solve this integral using the beta function.
The beta function is defined as,
B (α, β) = ∫ 0¹ t^(α-1) (1-t)^(β-1) dt
The beta function can be expressed in terms of gamma function as,
B (α, β) = (Γ (α) * Γ (β)) / Γ (α + β).
To solve the given integral, we need to write the given integrand in the form that can be represented using the beta function.
We can write the integrand as,
x² (1-x²³) dx = x² dx - x^8 dx
We can write the first term as,
x² dx = ∫ x^2 dx = (1/3) x³ + C1.
We can write the second term as,
-x^8 dx = -∫ x^7 d(x)= (-1/8) x^8 + C2.
Putting both the terms together, we get,
∫x² (1-x²³) dx= (1/3) x³ - (1/8) x^8 + C
The required integral is (1/3) x³ - (1/8) x^8 + C.
#SPJ11
Let us know more about Beta Function:https://brainly.com/question/31489881.
use a graphing device to find the solutions of the equation, rounded to two decimal places. (enter your answers as a comma-separated list.) cos(x) 4 x2 = x2
Answers
The solution for x² (3) = 0 can be found by looking at the x-axis intercept of the graph of y = x² (3) and rounding to two decimal places.
The given equation is cos(x) 4 x² = x². We need to find the solutions of the equation, rounded to two decimal places using a graphing device.
We can solve this equation by following the below steps: Step 1: Subtract x² from both sides of the equation cos(x) 4 x² - x² = 0cos(x) 3 x² = 0
Step 2: Factor out the common term x²cos(x) x² (3) = 0Step 3: Solve for x by using the zero-product property cos(x) = 0 or x² (3) = 0cos(x) = 0 has solutions 3π/2 + 2πn or π/2 + 2πn, where n is an integer.x² (3) = 0 has only one solution, which is x = 0.So, the solutions of the equation, rounded to two decimal places are:0.00, 1.57, and 4.71.
Note: The solutions for cos(x) = 0 can be found by looking at the x-axis intercepts of the graph of y = cos(x) and rounding to two decimal places. The solution for x² (3) = 0 can be found by looking at the x-axis intercept of the graph of y = x² (3) and rounding to two decimal places.
For more such questions on x-axis intercept
https://brainly.com/question/28473005
#SPJ8
in your own words, identify an advantage of using rank correlation instead of linear correlation.
Answers
An advantage of using rank correlation instead of linear correlation is that rank correlation measures the strength and direction of the relationship between variables based on their ranks rather than their exact values.
Rank correlation, such as Spearman's rank correlation coefficient or Kendall's tau, assesses the similarity in the ranking order of variables rather than their actual values. This characteristic of rank correlation makes it advantageous in situations where the relationship between variables is non-linear or when there are outliers present in the data. Rank correlation focuses on the relative position of data points, which helps mitigate the impact of extreme values that could disproportionately influence linear correlation. Additionally, rank correlation is suitable for capturing monotonic relationships, where the variables consistently increase or decrease together, even if the exact relationship is not linear.
To know more about rank correlation here: brainly.com/question/32519317
#SPJ11
Type an expression using x and y as the variables.
∂z/∂x = ____
∂x/∂t = ____
∂z/∂y = ____
dy/dt = ____
dz/dt = ____
∂z/∂x = ____
dx/dt = ____
∂z/∂y = ____
dy/dt = ____
dz/dt = ____
Use the Chain Rule to find dw/dt where w = cos 12x sin 4y, x=t/4, and y=t^4.
∂w/∂x = ____
(Type an expression using x and y as the variables.)
Answers
Using the chain rule to find dw/dt where w = cos 12x sin 4y, x=t/4, and y=t^4, we get; dw/dt = ∂w/∂x * dx/dt + ∂w/∂y * dy/dt where x = t/4, then dx/dt = 1/4 and y = t^4, then dy/dt = 4t^3
Substituting the above values into the equation, we have; dw/dt = (-12sin12xsin4y)(1/4) + (4cos12xcos4y)(4t^3)where x = t/4 and y = t^4.∂w/∂x = -12sin12xsin4y∂w/∂x = -3sin3tsin4t^4
A formula for calculating the derivative of the combination of two or more functions is known as the Chain Rule formula. Chain rule in separation is characterized for composite capabilities. The chain rule, for instance, expresses the derivative of their composition if f and g are functions.
According to the chain rule, the derivative of f(g(x)) is f'(g(x))g'(x). d/dx [f(g(x))] = f'(g(x)) g'(x). To put it another way, it enables us to distinguish "composite functions." Sin(x2), for instance, can be constructed as f(g(x)) when f(x)=sin(x) and g(x)=x2. This makes it a composite function.
Know more about chain rule:
https://brainly.com/question/31585086
#SPJ11
please help find the m∠ΚLM
Answers
Answer:
The answer for <KLM is 61°
Step-by-step explanation:
angle at cenre=2×angle at Circumference
122=2×<KLM
<KLM=122÷2
<KLM=61°
The data set below represents a sample of scores on a 10-point
quiz.
7, 4, 9, 6, 10,
9, 5, 4
Find the sum of the mean and the median.
15.50
13.25
14.25
12.25
12.75
Answers
The sum of the mean and the median of the given dataset, which consists of the scores 7, 4, 9, 6, 10, 9, 5, and 4, is 13.25.
To find the sum of the mean and the median of the given dataset, we first need to calculate the mean and median.
The dataset is: 7, 4, 9, 6, 10, 9, 5, 4.
To find the mean, we sum up all the numbers in the dataset and divide by the total number of data points:
Mean = (7 + 4 + 9 + 6 + 10 + 9 + 5 + 4) / 8 = 54 / 8 = 6.75.
To find the median, we arrange the numbers in ascending order:
4, 4, 5, 6, 7, 9, 9, 10.
Since we have 8 data points, the median will be the average of the two middle numbers:
Median = (6 + 7) / 2 = 6.5.
Now we can find the sum of the mean and the median:
Sum of mean and median = 6.75 + 6.5 = 13.25.
Therefore, the correct answer is 13.25.
To learn more about median visit : https://brainly.com/question/26177250
#SPJ11
An e-commerce Web site claims that 8% of people who visit the site make a purchase. A random sample of 15 people who visited the Web site is randomly selected. What is the probability that less than 3 people will make a purchase? The probability is _________
(Round to four decimal places as needed.)
Answers
The probability that less than 3 people will make a purchase is 0.886.
What is the probability?The probability that less than 3 people will make a purchase is calculated as follows;
The probability of less than 3 people is given as;
P(X < 3) = P(X = 0) + P(X = 1) + P(X = 2)
The probability for 0;
P(X = 0) = (15C₀)(0.08⁰) x (1 - 0.08)¹⁵⁻⁰
P(X = 0) = 0.286
The probability for 1;
P(X = 1) = (15C₁)(0.08¹) x (1 - 0.08)¹⁵⁻¹
P(X = 1) = 0.373
The probability for 2;
P(X = 2) = (15C₂)(0.08²) x (1 - 0.08)¹⁵⁻²
P(X = 2) = 0.227
The probability of less than 3 people is = 0.286 + 0.373 + 0.227
= 0.886
Learn more about probability here: https://brainly.com/question/24756209
#SPJ4
Number of late landing flights per day in Kuwait airport follows a Poisson process, therefore the time between two consecutive late landing flights is exponentially distributed with a mean of u hours. a) Suppose we just had one late landing flight, what is the probability that the next late landing flight will happen after 6 hours? (10 points] H=4.7 b) Suppose we just had one late landing flight, what is the probability that we observe the next late landing flight in less than 2 hours?
Answers
a) Given that the time between two consecutive late landing flights is exponentially distributed with a mean of u hours.
Therefore, the parameter λ of Poisson distribution is given as follows.λ = (1/u) = (1/4.7) = 0.2128 (approx)
Now, we need to find the probability of the next late landing flight will happen after 6 hours.P(X > 6 | X > 0)P(X > 6) = 1 - P(X < 6)
Where X is the time between two consecutive late landing flights.
P(X < 6) = F(6) = 1 - e^(-λ*6) = 0.570P(X > 6) = 1 - P(X < 6) = 1 - 0.570 = 0.43
Therefore, the probability that the next late landing flight will happen after 6 hours is 0.43.b) We need to find the probability that we observe the next late landing flight in less than 2 hours.
Therefore, the probability is calculated as follows.P(X < 2 | X > 0)P(X < 2) = F(2) = 1 - e^(-λ*2) = 0.201P(X < 2) = 0.201
Therefore, the probability that we observe the next late landing flight in less than 2 hours is 0.201.
To know more about probability, visit:
https://brainly.com/question/31828911
#SPJ11
The probability that we observe the next late landing flight in less than 2 hours is [tex]1 - e^(-2/u)[/tex].
a) Suppose we had one late landing flight, then the time between the two consecutive late landing flights would be exponentially distributed with a mean of u hours.
So, the probability that the next late landing flight will happen after 6 hours is given by P (X > 6) where X is the time between two consecutive late landing flights.
Now, the probability that the time between two consecutive events in a Poisson process with mean rate λ is exponentially distributed with mean 1/λ.
Here, we know that the time between two consecutive late landing flights is exponentially distributed with mean u. Hence, the mean rate of late landing flights is 1/u.
Therefore, [tex]P(X > 6) = e^(-6/u)[/tex]
Here, the value of u is not given.
Hence, we cannot find the exact probability.
However, for any given value of u, we can find the probability using the above formula.
b) Suppose we had one late landing flight, then the time between the two consecutive late landing flights would be exponentially distributed with a mean of u hours.
So, the probability that we observe the next late landing flight in less than 2 hours is given by P (X < 2) where X is the time between two consecutive late landing flights.
Using the same argument as in part a, we can see that X is exponentially distributed with mean u.
Therefore, [tex]P(X < 2) = 1 - e^(-2/u)[/tex]
Hence, the probability that we observe the next late landing flight in less than 2 hours is 1 - e^(-2/u).
To know more about probability, visit:
https://brainly.com/question/31828911
#SPJ11
Is the number of people in a restaurant that has a capacity of 200 a discrete random variable, a continuous random variable, or not a random variable? A. It is a discrete random variable. B. It is a continuous random variable. C. It is not a random variable.
Answers
The correct answer is A. It is a discrete random variable. A discrete random variable is a type of random variable that can take on a countable number of distinct values.
The number of people in a restaurant that has a capacity of 200 is a discrete random variable.
A discrete random variable represents a countable set of distinct values. In this case, the number of people in the restaurant can only take on whole numbers from 0 to 200 (including 0 and 200).
It cannot take on fractional or continuous values. Therefore, it is a discrete random variable.
The correct answer is A. It is a discrete random variable.
Visit here to learn more about discrete random variable brainly.com/question/30789758
#SPJ11
Given 7(0) = 3 2 ] Solve The Equations For T > 0: X1 A's 2x1 + 3.22 -21 + 2x2
Answers
In equation 7(0) = [3, 2], the solution for t > 0 is x1 = 2t + 3.22 - 21 and x2 = 2t.
The equation 7(0) = [3, 2] represents a linear system of equations with two variables, x1 and x2. By solving the system, we find that x1 is equal to 2t + 3.22 - 21 and x2 is equal to 2t.
To obtain these solutions, we can interpret the equation as follows: the coefficient of x1 is 2 in the first equation, and the constant term is 3.22 - 21. This means that as t increases, x1 will increase by twice the rate of t, starting from 3.22 - 21.
Similarly, the coefficient of x2 is also 2, indicating that x2 will increase at the same rate as t. Therefore, the solution for the given equations is x1 = 2t + 3.22 - 21 and x2 = 2t, where t > 0.
To learn more about linear equations
Click here brainly.com/question/20360246
#SPJ11
how many gallons of water should you add to 4 gallons of juice that is 20% water so the final mixture is 50 percent water
Answers
You should add 1 gallon of water to get the final mixture.
To determine the amount of water needed to achieve a final mixture of 50% water, we can set up a proportion based on the initial and final concentrations of water.
Let x represent the amount of water to be added in gallons.
The initial amount of water in the 4 gallons of juice is 20% of 4 gallons, which is 0.20 * 4 = 0.8 gallons.
The final amount of water in the mixture, after adding x gallons, will be (0.8 + x) gallons.
According to the proportion:
0.8 gallons / 4 gallons = x gallons / (4 + x) gallons
0.8 * (4 + x) = 4 * x
3.2 + 0.8x = 4x
3.2 = 4x - 0.8x
3.2 = 3.2x
x = 1
Therefore, you should add 1 gallon of water to the 4 gallons of juice to achieve a final mixture with 50% water.
To know more about mixture, refer here:
https://brainly.com/question/24898889
#SPJ4
10. Prove that if f is uniformly continuous on I CR then f is continuous on I. Is the converse always true?
Answers
F is continuous at every point x₀ ∈ I. Thus, f is continuous on an interval I.
Regarding the converse, the statement "if f is continuous on an interval I, then it is uniformly continuous on I" is not always true. There exist functions that are continuous on a closed interval but not uniformly continuous on that interval. A classic example is the function f(x) = x² on the interval [0, ∞). This function is continuous on the interval but not uniformly continuous.
To prove that if a function f is uniformly continuous on interval I, then it is continuous on I, we need to show that for any ε > 0, there exists a δ > 0 such that for any x, y ∈ I, if |x - y| < δ, then |f(x) - f(y)| < ε.
Since f is uniformly continuous on I, for the given ε, there exists a δ > 0 such that for any x, y ∈ I, if |x - y| < δ, then |f(x) - f(y)| < ε.
Now, let's consider an arbitrary point x₀ ∈ I and let ε > 0 be given. Since f is uniformly continuous, there exists a δ > 0 such that for any x, y ∈ I, if |x - y| < δ, then |f(x) - f(y)| < ε.
Now, choose δ' = δ/2. For any y ∈ I such that |x₀ - y| < δ', we have |f(x₀) - f(y)| < ε.
Therefore, for any x₀ ∈ I and ε > 0, we can find a δ' > 0 such that for any y ∈ I, if |x₀ - y| < δ', then |f(x₀) - f(y)| < ε.
This shows that f is continuous at every point x₀ ∈ I. Thus, f is continuous on interval I.
Learn more about arbitrary point:
https://brainly.com/question/19195471
#SPJ11
exercise 1.12. we roll a fair die repeatedly until we see the number four appear and then we stop. (a) what is the probability that we need at most 3 rolls?
Answers
The probability that we need at most 3 rolls to see the number four appear is 7/8.
we can analyze the possible outcomes. In the first roll, there are 6 equally likely outcomes since each face of the die has an equal chance of appearing. Out of these 6 outcomes, only one outcome results in seeing the number four, while the other 5 outcomes require additional rolls. Therefore, the probability of needing exactly one roll is 1/6.
In the second roll, there are two possibilities: either we see the number four (with a probability of 1/6) or we don't (with a probability of 5/6). If we don't see the number four in the second roll, we proceed to the third roll.
In the third roll, the only remaining possibility is seeing the number four, as we must stop rolling after this point. The probability of seeing the number four in the third roll is 1/6.
To find the probability of needing at most 3 rolls, we sum up the probabilities of these three independent events: 1/6 + (5/6)(1/6) + (5/6)(5/6)(1/6) = 7/8. Hence, the probability that we need at most 3 rolls is 7/8.
Learn more about probability here:
https://brainly.com/question/31828911
#SPJ11